
Avevo promesso di scrivere un articolo meno teorico, ed eccomi qua. Inizio da ora a predisporre le basi per il traduttore, e non posso farlo senza considerare almeno uno degli strumenti messi a disposizione per gli autori di giochi di avventura testuale dell’epoca.

Qualcuno mi ha proposto di partire da questo gioco, una avventura testuale per il Commodore 64… chissà se si può fare, senza chiedere il permesso all’autore?
Premetto subito che l’approccio che utilizzo è indipendente dal framework utilizzato per realizzare l’avventura, e funziona anche a prescindere dall’avventura stessa. Questo per rassicurare il buon Bonaventura di Bello che, nel suo commento, scrive:
Tieni presente che i framework di sviluppo utilizzati per le vecchie AT (Quill, GAC, PAW, ecc.) hanno caratteristiche diverse l’uno dall’altro, quindi unificare la ‘conversione’ è un obiettivo piuttosto utopistico.
Comunque, per non rimanere sul teorico da un formato bisognerà pur partire, ed è per questo che ho scelto lo Z-code, che è uno degli standard più diffusi per la produzione di avventure testuali.
Lo Z-code è il linguaggio macchina letto e interpretato dalle macchine virtuali Z-machine, che a loro volta sono dei piccoli programmi sviluppati da Joel Berez e Marc Blank nel 1979, per implementare le avventure testuali della Infocom dai primi anni ’80.
Quello che faceva questa azienda, in parole povere, era prendere il codice sorgente dei suoi programmatori e compilarlo, producendo appunto file contenenti istruzioni per una macchina… inesistente.

Zork fu la prima avventura testuale ad utilizzare lo Z-code: in effetti, questo linguaggio prende il nome proprio dall’iniziale di questo gioco!
Può sembrare un’assurdità, ma la soluzione di compilare i sorgenti in un codice “intermedio” all’epoca era assai vantaggiosa per molte ragioni, non ultima quella che il mercato degli home computer era fortemente frammentato, e le macchine erano incompatibili tra loro. Scrivere avventure per ognuna era economicamente improponibile perché avrebbe significato riscrivere lo stesso gioco tante volte quanti erano gli elaboratori: realizzare, per ognuna, un solo interprete era invece più remunerativo.
Fu un concetto così ovvio ed economicamente vincente che, anni dopo, lo fece suo Java (e, pensate, spacciandolo per una innovazione!)… avete presente il bytecode? Compile Once Run Everywhere? Stessa cosa!
Nel corso degli anni si sono succedute le versioni, e così il linguaggio si è arricchito di istruzioni e comportamenti sempre più complessi.
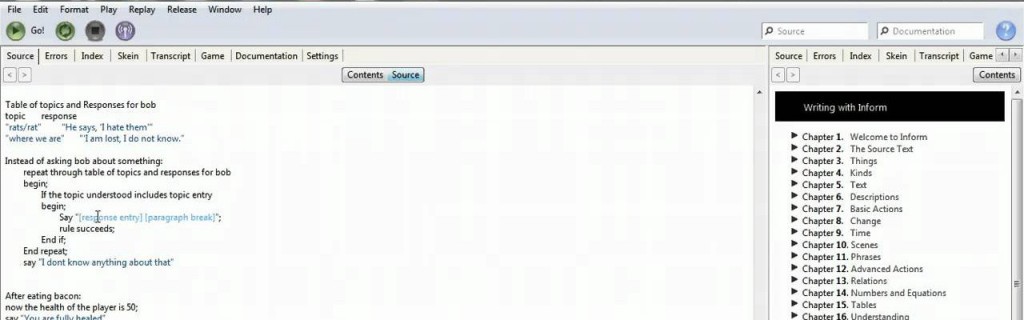
Un esempio di scrittura avventure con Inform.
Gli anni passano ancora, purtroppo la Infocom nel 1989 viene meno ma non l’idea di un compilato intermedio: tant’è che, nei primi anni novanta, Graham Nelson stilò una vera e propria specifica dello standard, facendo un vero e proprio lavoro di retroengineering. È lui, peraltro, l’autore originale di Inform che, al momento, è anche uno dei tool più utilizzati per scrivere avventure testuali.
Chiusa la dovuta parentesi storica, torniamo alla nostra idea di partenza.
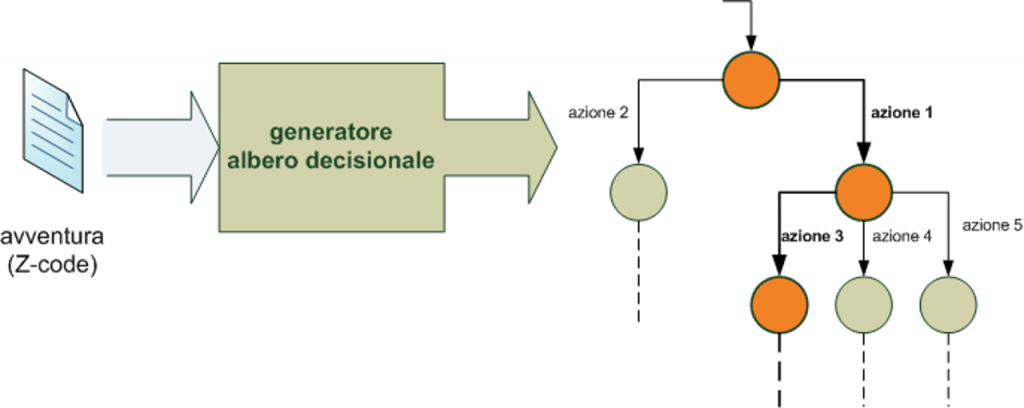
La prima fase consiste nella traduzione dell’avventura in un albero decisionale.
Seguendo quello che avevo scritto qui e ricapitolando per non perdere il filo, abbiamo bisogno di tradurre una storia scritta in Z-code nell’albero decisionale. Una volta fatto questo, abbiamo bisogno di analizzare man mano questo albero, per rendere scene e azioni complesse come paragrafi e opzioni, e costruire quindi il librogioco bello e finito.
Qui arriviamo al primo problema: come facciamo a leggere il codice? Costruire un nuovo interprete Z-code è fuori discussione per questioni di tempo, e adattare uno già esistente è ancora più difficile, a causa della necessità di studiare tutti i sorgenti. Qualcuno ha anche suggerito di partire dai sorgenti dell’avventura testuale: potrebbe essere una strada percorribile, se non fosse che il linguaggio di Inform è davvero molto complesso in termini linguistici. Praticamente, una difficoltà paragonabile (se non superiore!) a implementare la Z-Machine.
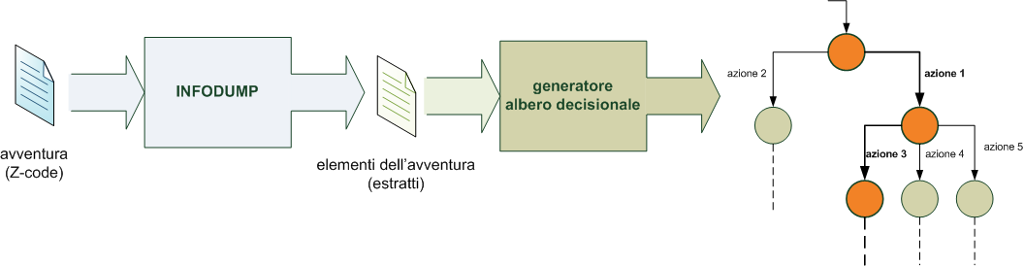
Il primo passo consiste nell’estrarre i dati con l’utilità INFODUMP.
Per fortuna ci vengono in aiuto un insieme di tool, scritti in origine da Mark Howell e ora manutenuti da Matthew Russotto. In particolare, la mia idea è quella di partire, invece che dal file binario, dalla sua conversione in una forma leggibile.
Per far questo utilizzeremo il programma INFODUMP, che è uno strumento molto utile per estrarre tutte le informazioni presenti in un file Z-code: oggetti, parole, verbi, azioni, … che saranno gli elementi di base dai quali partiremo per costruire gli input possibili.
Poiché non voglio essere teorico, mi piacerebbe analizzare un’avventura specifica, ma non so quale scegliere: perché non me la indicate voi, esprimendovi in questo sondaggio?